
章:今回のアプリ構成「1社集中分析ボット」
いきなり複数のサイトを比較するのは難易度が高いため、まずは「1つのURLを確実に読み解く基礎」を固めることにしました。
- LINE公式アカウント:私(ユーザー)とAIが会話する窓口。
- Dify(チャットフロー):送られてきたURLをどう処理するか考える「脳」。
- Jina Reader:AIが直接見られないウェブサイトを、テキストデータに変換して「読み聞かせてくれる」通訳。
この3つを連携させるだけ……のはずが、ここからが本当の戦いでした。
第2章:【完全ガイド】アプリの作り方と設定の全貌
読者の皆さんが同じ罠にハマらないよう、私が最終的に成功した設定を「1ミリの妥協もなく」公開します。
① 開始ノード(Start)
ここはあえて「入力変数」を空っぽにします。LINEから送られたメッセージは、Difyのシステム変数 {{sys.query}} に自動的に格納されるからです。変数を増やしすぎないことが、エラー回避の第一歩でした。
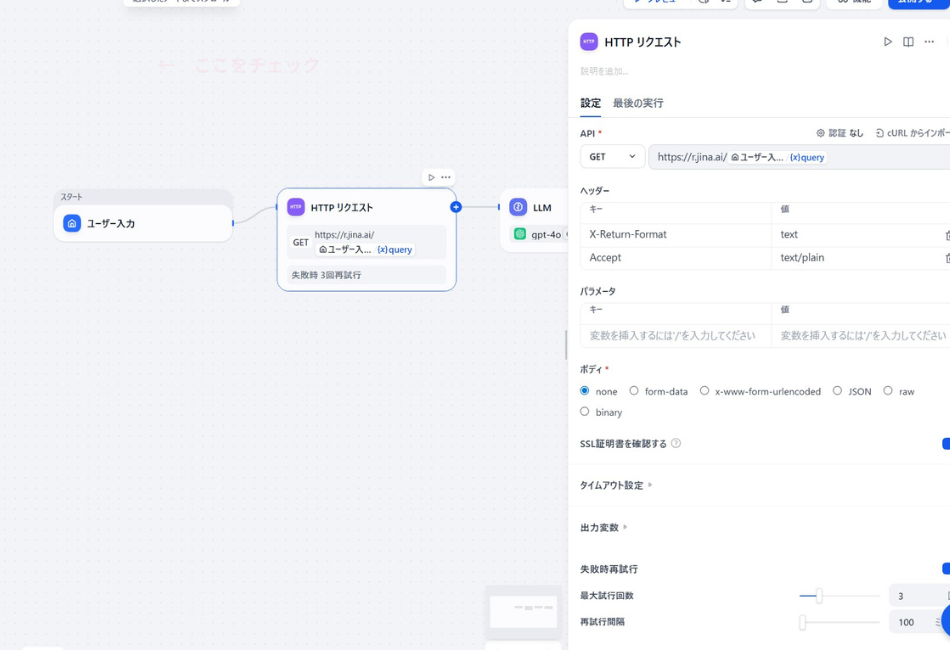
② HTTPリクエスト・ノード(最重要!)
ここが心臓部です。外部サービス「Jina Reader」を呼び出します。
- API設定:
GETを選択。 - URL:
https://r.jina.ai/{{sys.query}}- ★超重要ポイント:
jina.ai/の後の**「/(スラッシュ)」**。これがないと、AIは住所の区切りがわからず、即座にエラーを出します。
- ★超重要ポイント:
- ヘッダー設定:
- キー:
X-Return-Format/ 値:text - キー:
Accept/ 値:text/plain
- キー:
③ LLMノード(分析の実行)
モデル選びが運命を分けます。
- モデル名:
gpt-4o- 以前の
gpt-4では、情報量が多いサイトを読み込む際に「お腹いっぱい(文字数オーバー)」でパンクしてしまいました。最新のgpt-4oなら、胃袋(コンテキスト)が大きく、安定して処理できます。
- 以前の
- SYSTEMプロンプト: 「あなたはプロのアナリストです。以下のサイト情報から、価格・特徴・強みを抽出し、Markdownの表で回答してください」
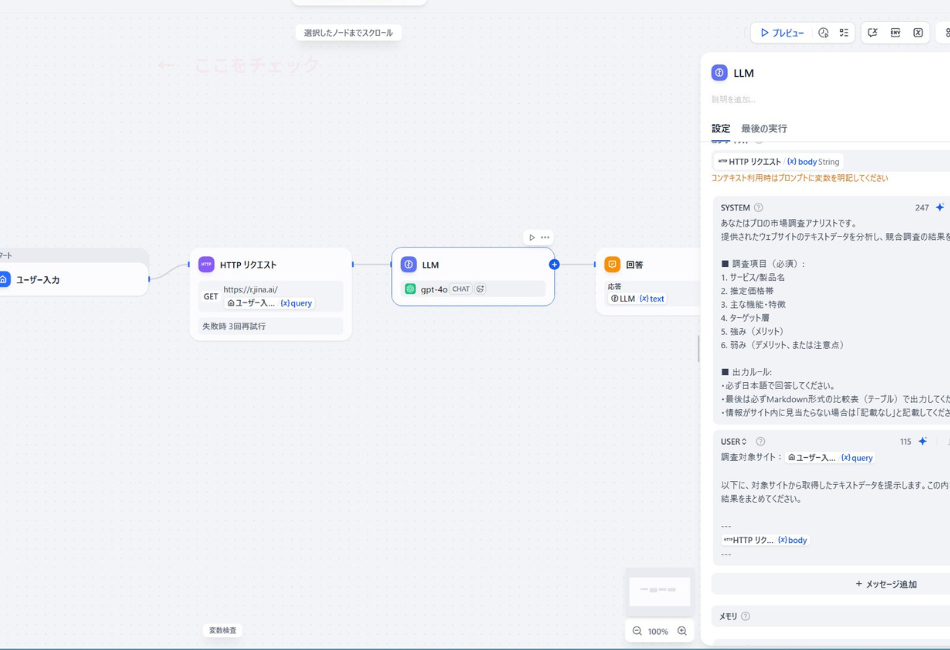
④ 回答ノード(Answer)
最後に、LLMが生成した {{text}} を出力するように設定します。これでLINEに返信が届きます。
第3章:私が直面した「3つの絶望」とその突破口
ここがこの記事のメインディッシュです。IT初心者が必ずと言っていいほど踏む地雷を解説します。
落とし穴1:スラッシュと空白の「1文字」の罠
Difyの設定画面で、https://r.jina.ai/ と入力した際、最後にスラッシュを入れ忘れたり、あるいは変数 {{sys.query}} との間に**「半角スペース」が1つ入ってしまったりしました。 システムはたった1文字のミスも許してくれません。「Invalid port」や「400 Bad Request」が出たら、まずは「隙間がないか」「スラッシュがあるか」**を指差し確認してください。
落とし穴2:URL入力時の「https://」重複問題
これが一番盲点でした。LINEからテストで https://example.com と送ると、設定画面の https://r.jina.ai/ と合体して、住所が https://r.jina.ai/https://... と二重になってしまいます。 正解は、**「URLを入力する時は『example.com』から書く」**こと。この「引き算」の考え方が、連携を成功させる鍵でした。
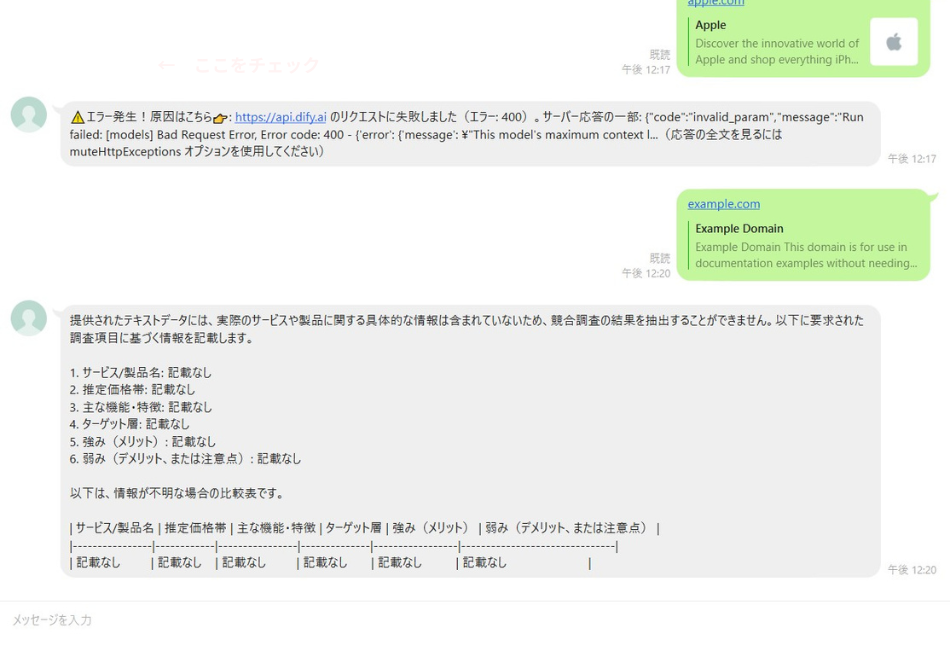
落とし穴3:AIの「胃袋」の限界
Appleやスターバックスのような巨大なサイトを読み込もうとすると、AIが「長すぎて読めない!」とエラーを出します。 「SUCCESS」の緑文字を見るためには、情報量が少ない example.com でまずは成功体験を積み、本番では gpt-4o のような高性能モデルに頼る勇気が必要です。
第4章:SUCCESS!「記載なし」の表に震えた日
試行錯誤すること数時間。ついにLINEに返ってきたのは、 | 項目 | 内容 | | 価格 | 記載なし | という、一見すると中身のない表でした。
しかし、私はこれを見て震えました。「私の作った仕組みが、ネットの海を渡り、外部のサイトを読み取って、私のLINEまで情報を持ち帰ってきた」。その事実が、何よりも嬉しかったのです。
結びに:49歳、IT未経験でも「AIの飼い主」になれる
今回の開発を通して学んだのは、AIを使いこなすには「プログラミング知識」よりも、エラーメッセージという「AIの声」に耳を傾ける**「根気」**が必要だということです。
「1つのサイトが読めるようになった」というのは、大きな一歩です。次は、複数のサイトを同時に比較し、本当の意味での「競合調査ボット」へ進化させていくつもりです。
何とかどはまりしないようにしたいです。次回も是非お楽しみに!


コメント